
I am text block. Click edit button to change this text. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Organizations are quickly migrating from virtual machines (VMs) to a cloud-native platform constructed around container technologies like Kubernetes to deal with high application availability, easier scalability and resilience.
In this blog, we discuss key factors to consider while migrating VM-based applications to Kubernetes. This may be useful for those who are currently running their microservices without any containerization, or have containerized but without any orchestration and want to provide high availability, scalability and failover.
A Deployment Model without K8s
Take a look at the following image — a diagrammatic representation of a deployment model with Kubernetes where microservices are running on the same VM or distributed across multiple VMs.
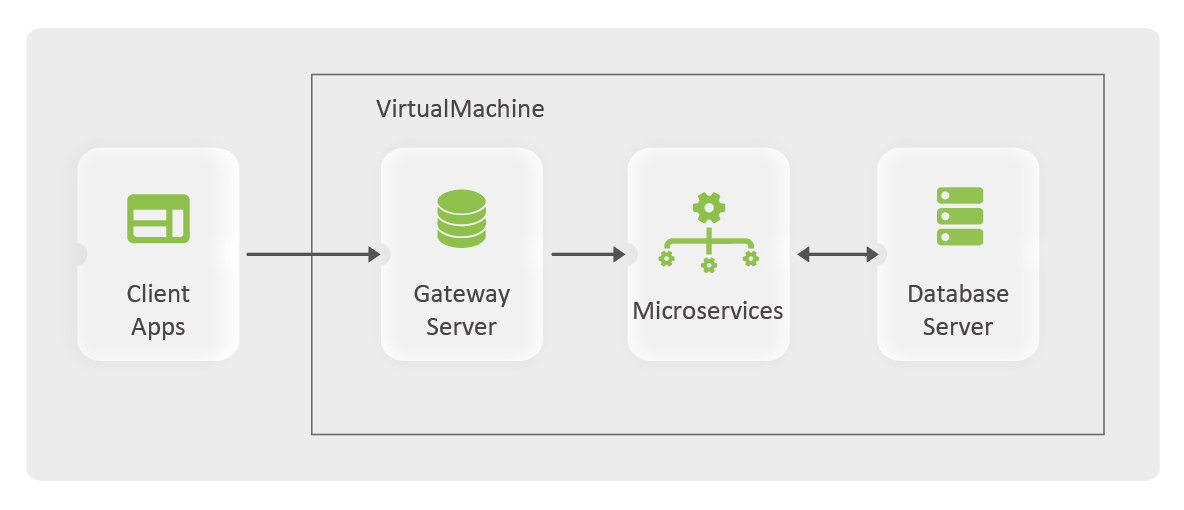
According to this model, inter-service communication would be possible with the following options:
- Services point directly to localhost:{{port}}
- Services point to arbitrary service name, for example, dbhost:5432, and maintain IP address against such service names in /etc/hosts file as shown below,
#: vi /etc/hosts
127.0.0.1 dbhost
Now, let’s discuss the challenges with this model.
Scalability
- It is not possible to run multiple service instances with the same port on the same VM. This restricts scaling up the application whenever it is required to serve large volumes of requests. Hence, horizontal scaling is not feasible.
Load Balancing
- Multiple service instances may run on different VMs with multiple entries in the hosts file to achieve scalability. Even then, caller service cannot invoke distributed instances at once of such a target service.
- A dedicated load balancer is required to overcome this. The load balancer will resolve the hostname against the IP address of the VM where the service instance is running.
Failover
- It is important that application uptime is high. A service may abruptly stop working because it is out of memory or insufficient disk space.
- In such cases, service should auto-restart or another service instance should spawn.
- Regular health check probes need to be implemented to detect and take a corrective course of action in such scenarios.
Availability
- In an instance when the entire VM shuts down abruptly, the whole application is down.
- Providing application uptime during release cycles is also a challenge. End users may experience downtime when application upgrade is in progress.
Monitoring
- With self-managed services, it is necessary to implement additional monitoring solutions that would provide visibility of all the services showing their health, memory consumption and other such insights.
Migration to Kubernetes
Docker
(Note: You may skip this section if microservices are already packaged inside docker images.)
A docker image is a lightweight, standalone, executable package of software that includes everything needed to run an application.
To containerize a microservice, here is an overview of the steps,
- Write Dockerfile that specifies base image, directory structure, application artifacts and an entrypoint script that launches the application.
- A CI/CD pipeline that builds service, builds a docker image and pushes it to a repository. (The pipeline can also be extended till the actual deployment of the docker image to a target node). Bitbucket pipelines or Jenkins pipelines are possible candidates.
Kubernetes
Kubernetes is an open source system for automating deployment, scaling, and management of containerized applications. It can be configured in cluster mode or on a single machine i.e. minikube that is suitable for local testing.
Cluster
Microservices are run inside a Kubernetes cluster. A cluster typically consists of —
- A master node (VM)
- One or more worker nodes (VM)
Services are run on worker nodes whereas the master node manages the entire cluster. Outside the cluster, a storage VM contains persistent data. The reason why the storage VM is outside the cluster is to prevent data loss in the event a total cluster failure.
>> You can follow this official documentation to setup a Kubernetes cluster.
Objects
Once the docker image is ready and pushed onto a repository, it is time to add Kubernetes resources for microservices.
Below is a list of the bare minimums required:
- Deployment
- When a docker image is run, a container is created, with its own IP address.
- On the Kubernetes cluster, a container is run inside a pod, which contains one or more containers and has its own IP address.
- Deployment is the type of object that creates pods. Pod creation can be autoscaled based on the resource utilization or the static pod count can be set. For a microservice, there will be one deployment that acts like a group of service instances.
- StatefulSet
- There are services that need to persist the data, such as Postgres, RabbitMQ and ElasticSearch.
- It is advised to use StatefulSet instead of a deployment for such services.
- Persistent Volume
- Persistent data from the containers should be kept on a storage VM or on a cloud service. Persistent Volume object contains configuration of such target locations, along with the storage types and required sizes.
- Target locations could be NFS or cloud services like Azure Files, Azure Disk, AWS EBS, and AWS S3.
- Instead of associating with Persistent Volume directly, pods are associated with Persistent Volume Claim, which demands for a certain storage type and size. Whichever Persistent Volume satisfies that criteria, is then linked with Persistent Volume Claim.
- When mounting directory on storage node, it is important to provide fsGroup under pod specifications as follows,securityContext:
fsGroup: 2000Note: The “2000” mentioned here is the group permission of the target directory on the storage node.
- Service
- A service object is a key for inter-service communication inside the Kubernetes cluster. For a microservice, there should be a Kubernetes service present.
- The service name should be the same as the hostname used by the application to call another service.
- Kubernetes maintains an endpoint mapping of service name vs IP addresses of pods. Here, hostname resolution is done out-of-the-box, eliminating the need to maintain entry in the hosts file.
- By default, service type is ClusterIP which is not exposed outside the Kubernetes cluster, but a NodePort type of service is. A LoadBalancer service type is applicable in the cloud where a public IP address associated with the cloud load balancer service is assigned to the Kubernetes service.
- Ingress
- Ingress are the rules that redirect certain requests to a specific service based on the request path. These are read by the Ingress Controller, responsible for routing and load balancing requests. For example, NGINX Ingress Controller (ingress-nginx) is maintained by the Kubernetes community and provides yaml directives that can be used while writing ingress rules.
- Other options for Ingress Controller are HAProxy, NGINX Plus and Azure Gateway Ingress Controller.
- Ingress Controller acts like a load balancer because it forwards a specific request to the destination pod.
- Along with ingress rules, it is necessary to install Ingress Controller, which has its own pod and service. The service is of type NodePort. This would be the single entry point to the entire Kubernetes cluster.
- Secret
- Secret is a type of object that maintains data in the form of key and value, where values are base64 encoded.
- It is also important to create a secret that has credentials for pulling docker images from a private repository. The secret name should be then provided against imagePullSecrets in pod specification.
- ConfigMap
- Similar to Secret, ConfigMap can be used to store data in key and value form, which could then be passed to pod as an environment variable. Values are not base64 encoded and stored in plain text form.
- Namespace
- Namespace is the logical separation of Kubernetes objects inside the cluster, for example, a namespace with infrastructure services containing a database server could serve Dev and QA pods from their respective namespaces.
- If no namespace is provided, then all the resources are deployed in the default namespace.
- Deployment Model
- Although the ingress controller is capable of SSL termination, this could also be delegated to a gateway service running on the master node.
- Gateway service would conduct an SSL termination and forward requests to the Kubernetes cluster.
Take a look at what a final deployment model would look like:
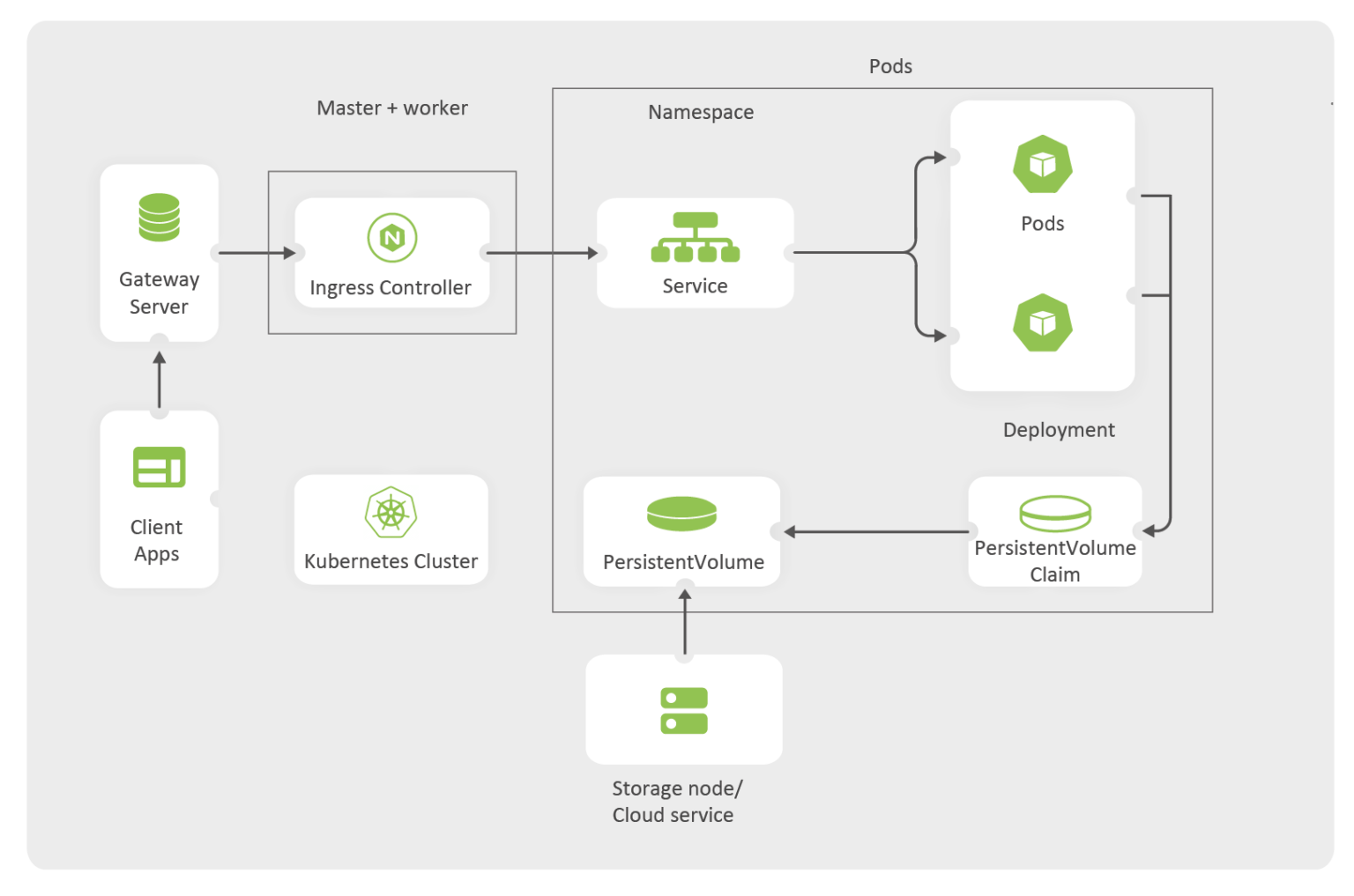
Notice how the ingress controller is the single entry point to access the cluster. There should be a Kubernetes service and a deployment for each microservice. Ingress rules are implemented by Ingress Controller. Persistent Volume and Persistent Volume Claim can be shared across multiple pods.
Packaging and Deployment
- Kubernetes resources can be deployed using the following command:
kubectl apply -f resource.yaml
where the resource.yaml contains Kubernetes resources. - This approach does not involve packaging and release considerations. Helm can be used to package and automate deployment.
- With Helm, we could define, install, and upgrade Kubernetes resources. Helm charts need to be created that contain Kubernetes resources in a template form, and their values can be injected from external files.
- On top of Helm, automating helm charts can be done using tools like Helmfile or Helmsman.
Key factors to keep in mind
You may be still contemplating your move to Kubernetes, or may have already started off on your journey. However, it would be incomplete without highlighting the following points:
- Kubernetes provides support for horizontal scaling of microservices.
- Load balancing of the requests is taken care of by the ingress controller.
- With the pod states, Kubernetes is able to spawn additional pods, providing a failover capability.
- A pod-readiness state can be controlled with a readiness probe, which provides feasibility to upgrade/rollback services without impacting the application uptime.
- A Kubernetes dashboard provides an out-of-the-box monitoring solution to monitor the entire cluster.
How to maximise Kubernetes for better application infrastructure
Kubernetes is the perfect solution for application scalability, visibility, effort-savings and rollouts, while taking care of the complete application infrastructure and easing the overall development lifecycle. However, the perfect solution needs a worthy system integration partner for a streamlined implementation.
GS Lab boasts of extensive hands-on experience, working with container orchestration tools and our product engineering expertise has helped in more than 2,000 booming product releases.
>> Here’s an example of GS Lab’s successful VM migration for a WAN company where we successfully migrated five clusters in one year, each consisting of more than 25 microservices hosted by more than 50 AWS instances. Click here to read now: https://www.gslab.com/case-studies/migrating-wan-product-from-microservices-to-kubernetes
Author
Mayur Dhande | Senior Software Engineer
Mayur has 7+ years of experience in Software Development. He is an experienced backend developer and works on technologies in the cloud integration and healthcare domain. Mayur possesses industry experiences in Web Development, Microservices, DevOps and Azure Cloud. His area of interest includes Web development, Automation and Machine Learning.


